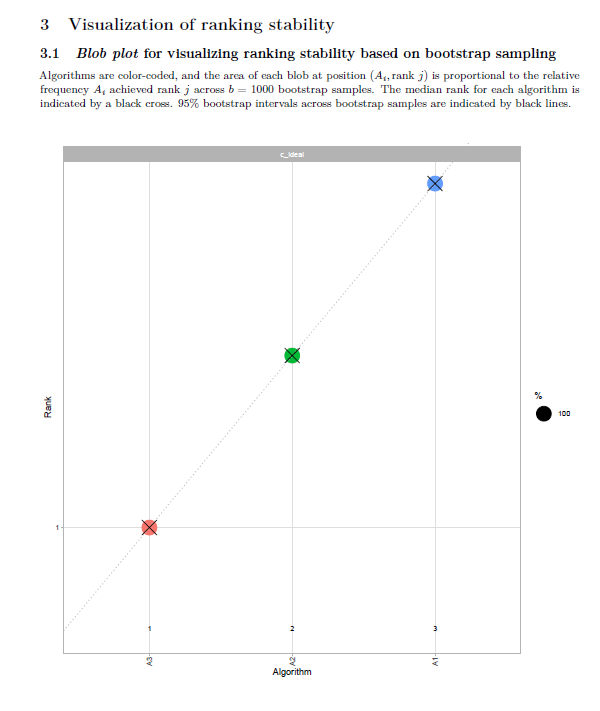
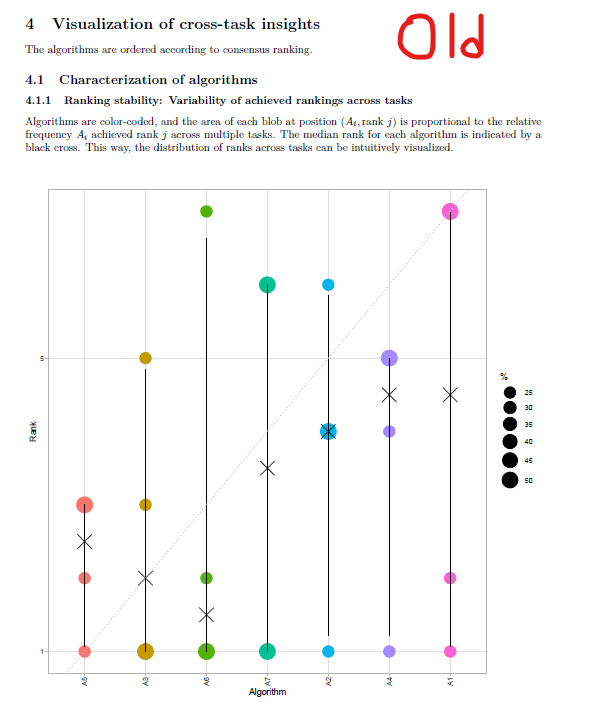
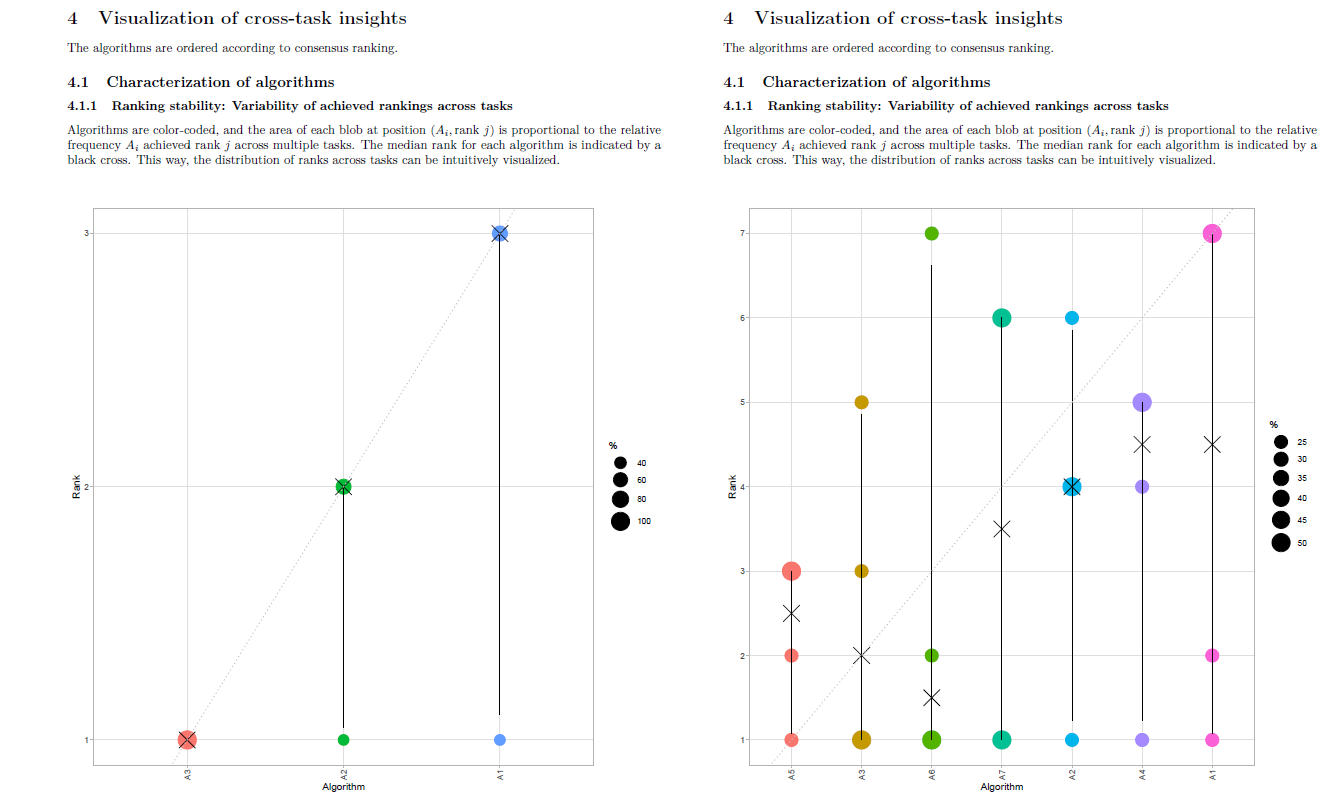
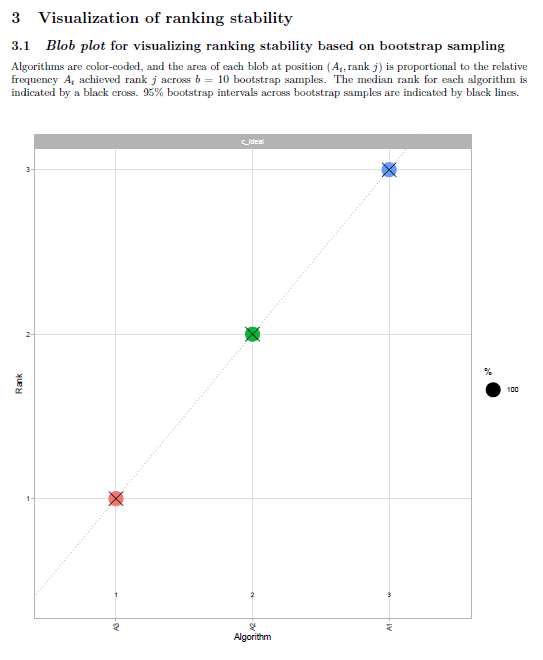
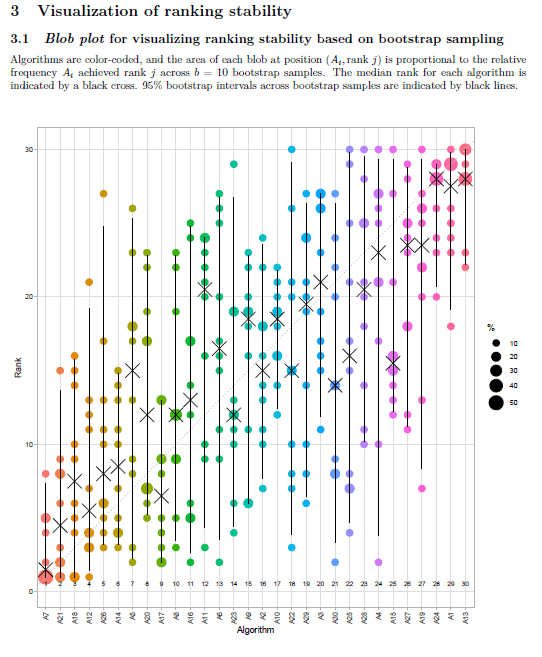
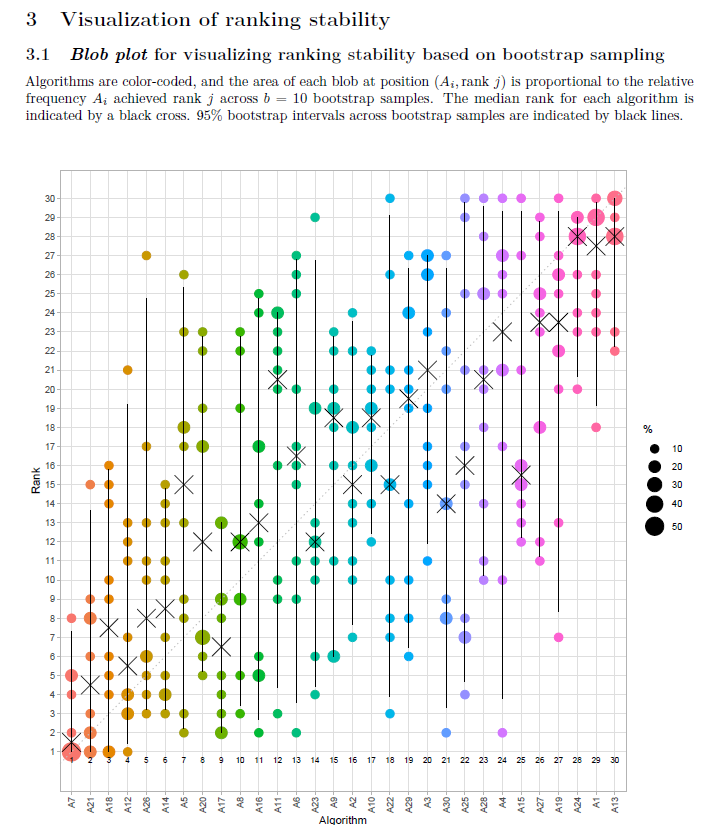
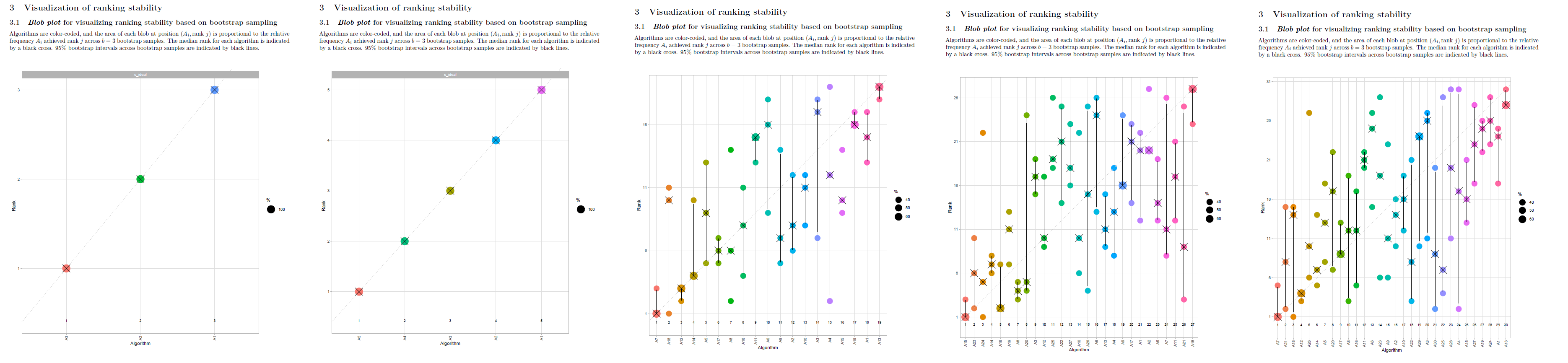
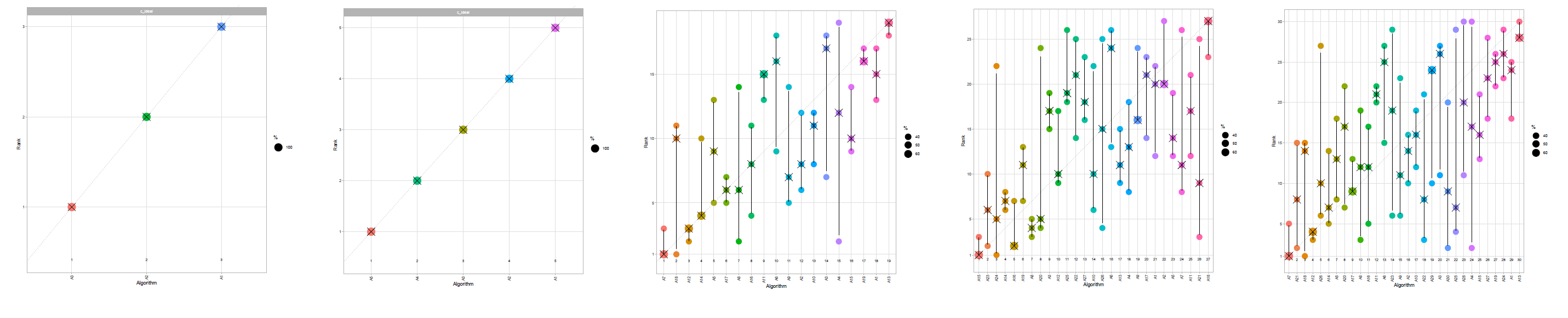
In the report, the y-axis of the blob plots (in sections 3.1, 4.1.1, 4.1.2, 4.2.1) are always scaled to [x 5] range, regardless of the number of algorithms in the data. If there are less than 5 algorithms in the data, this can create confusion, as shown in the image below:
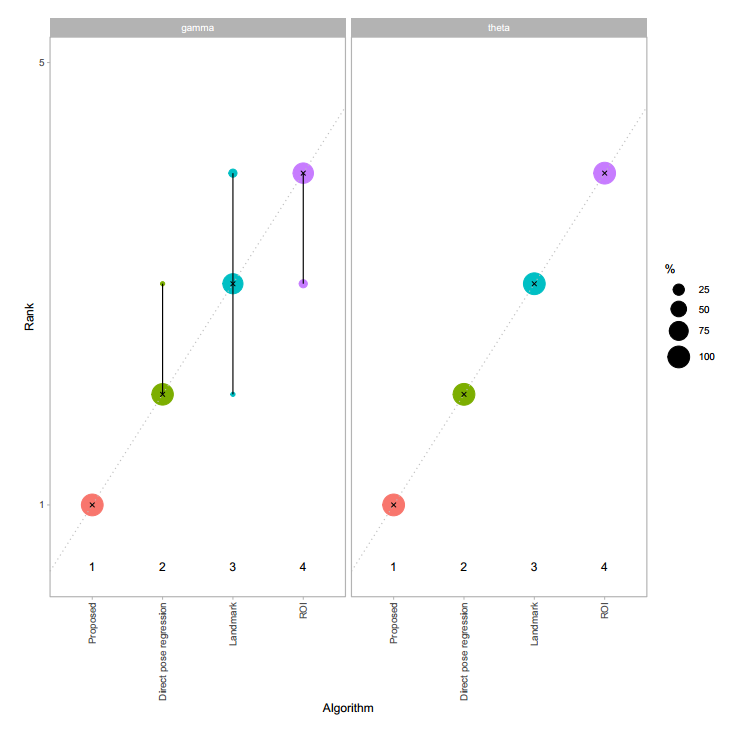
The solution can be scaling y-axis to [x #algorithms] range if number of algorithms <5.
Sample data and report are attached: