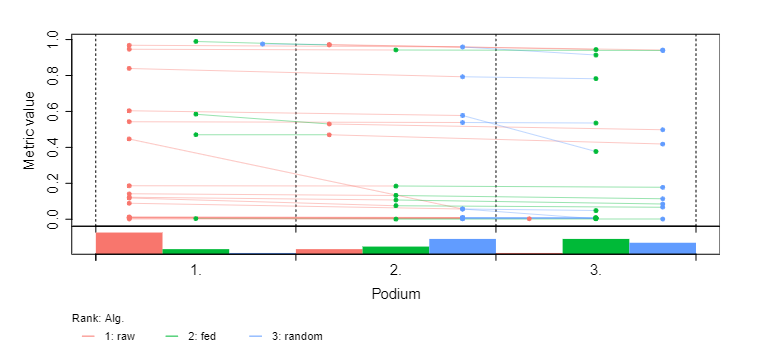
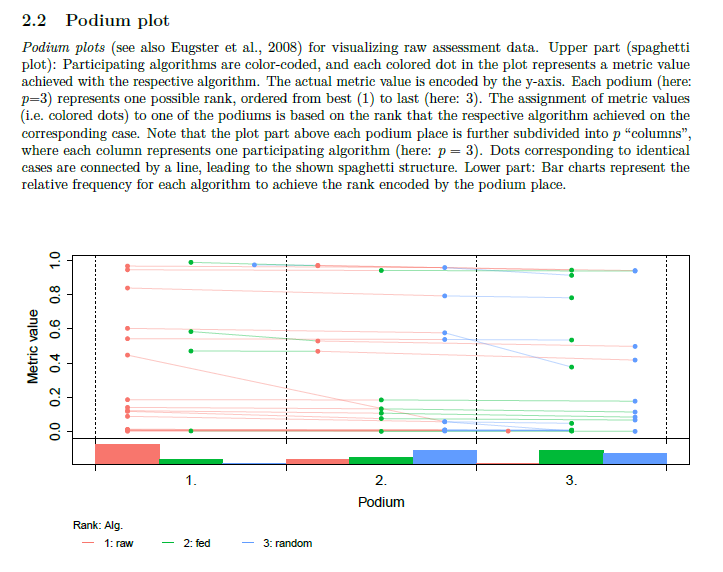
When using the current version of the web-based challengeR, the attached config and CSV file, the bars in the lower part seem not to represent the distribution of dots in the upper part of that podium position.
| eisenman | |
| May 6 2022, 12:59 PM |
| F2539653: T29167_test_with_R4_2_0.pdf | |
| May 13 2022, 1:40 PM |
| F2539646: image.png | |
| May 13 2022, 1:40 PM |
| F2539543: image.png | |
| May 12 2022, 5:15 PM |
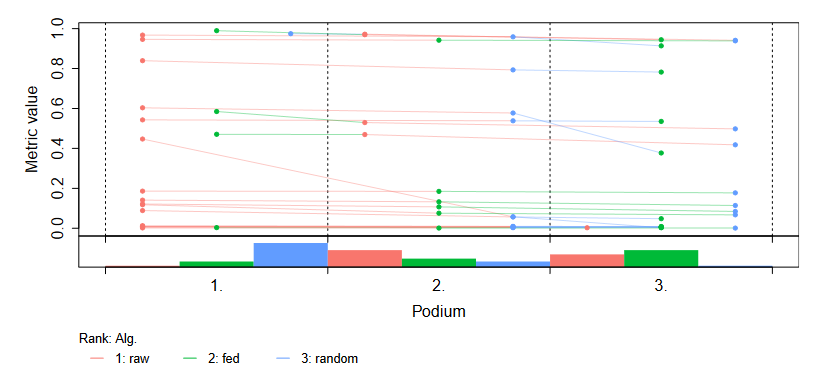
| F2538080: podium_plot_correct.PNG | |
| May 6 2022, 1:04 PM |
| F2538074: podium_plot_error.png | |
| May 6 2022, 12:59 PM |
| F2538073: podium_plot_config.png | |
| May 6 2022, 12:59 PM |
| F2538072: TL_challengeR.csv | |
| May 6 2022, 12:59 PM |
When using the current version of the web-based challengeR, the attached config and CSV file, the bars in the lower part seem not to represent the distribution of dots in the upper part of that podium position.
I have detected the same problem with R 4.2.0. It seems, it is caused by major version change of R. We need to go deeper and find the source of this change.
From the change log for R 4.2.0
GRAPHICS:
- The graphics engine version, R_GE_version, has been bumped to 15 and so packages that provide graphics devices should be reinstalled.
Maybe just reinstalling the package helps?
I have tried with fully fresh setup (first uninstalled everything, then reinstalled all from scratch) but the problem still exist unfortunately :/
Update: I go deeper with debugging and some reverse engineering. The source of the problem is the miss-ranking of the algorithms. When we use testThenRank and rankThenAggregate methods, the ranking of the algorithms seems wrong, as it is seen on the screenshot (marked with red rectangular). There is no problem with aggregateThenRank method so far.
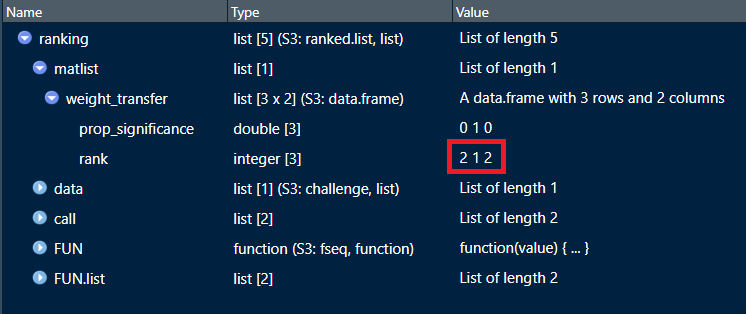
I am working on to reveal what causes this problem.
Finally, I could find the source of the bug. 😊 It is caused by changed output type of unique() function in R:Base from R-3 to R-4.
Inside of testBased.R function, the list of the algorithms are generated by algorithms=unique(object[[by]]) code at here
The problem starts here. In R-3, the class of the output is:
> class(algorithms) [1] "factor"
while it is different in R-4
> class(algorithms) [1] "character"
factor class has additional level information:
> levels(algorithms) [1] "fed" "random" "raw"
while there is no such a definition in character class. I think some further executed functions need level value. Otherwise, the order can be wrong, and the plots can be wrong, as we see here. I just changed line 199 with:
algorithms=factor(unique(object[[by]]))
Then it seems problem solved (You may also see the attached whole report.):
I think we need to handle these next steps:
Thanks Emre!
Thats a weird change. I didn't find any mention in R changelog.
probably instead of
algorithms=factor(unique(object[[by]]))
it will be preferred
algorithms=levels(object[[by]])
Because if object[[by]] is a factor, your solution might be dependent on the ordering of algorithms in the data set, which should be tested (effect might be different for different occurrences)
On the other hand, it has to be tested if object[[by]] is always a factor (i.e. if it depends on if algorithm is defined as factor in the data set or may be also defined as string (character)).
thanks again for tracking this down!
Hi again,
I have tried algorithms=levels(object[[by]]) but it does not work. The output is always NULL
On the other hand, maybe a quick and temporary solution can be fixing R version in 3 (>3.5.2) for webchallengeR system, because it seems it is necessary to test so many scenarios before modifying unique() functions among the whole package.
if the output is NULL, object[[by]] is not a factor, i.e. class(object[[by]]) is "character", in this case you need to use use unique() and probably your solution
algorithms=factor(unique(object[[by]]))
may be correct, please test carefully with different ordering of test cases in the data set to make sure ordering of data matrix doesn't have an impact
Hi again :)
I spent my free time during a long train journey for discovering the main source of the problem mentioned here. 😃
I compared everything with R version 3 and 4 step-by-step. Finally, I could locate the main difference is coming from somewhere surprising: read.csv() function. In R 3, the character strings were converted to factors while reading CSV file. However, it has been changed in R 4. Strings are not converted anymore, they are saved as "character" class.
The option is controlled by stringsAsFactors parameter in read.table() function, which is used by read.csv() function. The default value of stringsAsFactor parameter has been changed TRUE to FALSE in R 4:
data.table has always set stringsAsFactors=FALSE by default. In R 4.0.0 (Apr 2020), data.frame's default was changed from TRUE to FALSE and there is no longer a difference in this regard; see [stringsAsFactors, Kurt Hornik, Feb 2020]
Source: https://github.com/Rdatatable/data.table/blob/96cdef6d03f3fb296778cc7a5550f704d011e083/vignettes/datatable-faq.Rmd#L397
I just changed data reading line to data_matrix <- read.csv("data.csv", stringsAsFactors=TRUE) and all problems solved in a single line! 🙃
Further steps:
Good news: It seems the issue solved now easily without touching any source file in challengeR. We only need to update documentation.
Bad news: It can be problematic in the future. It is explained here why this parameter has been decided to change:
Finally, looking at modern alternatives to data frames shows that data.table uses stringsAsFactors = FALSE by default, and tibble never converts.
Hence, in the R Core meetings in Toulouse in 2019, it was decided to move towards using stringsAsFactors = FALSE by default, ideally starting with the 4.0.0 release.
Eventually, the stringsAsFactors option will thus disappear.
Source: https://developer.r-project.org/Blog/public/2020/02/16/stringsasfactors/
The last line simply says that, we will have this problem some time in the future. 😨 Maybe we should discuss what kind of strategy we are supposed to follow.
Thank you so much @aekavur ! It helps a lot to understand the reason finally!
In this case defining algorithm as a factor internally is probably the best solution and not a big change.
I first thought, the best solution would be to add in as.challenge() (file challengeR.R) at the very beginning after
object=as.data.frame(object[,c(value, algorithm, case, by, annotator)])
the definition of algorithm as a factor:
object[[algorithm]] <- as.factor(object[[algorithm]])
which would be quite clean (this is the place where it had been defined as a factor before when as.data.frame() hat default strigsAsFactors=TRUE). As far as I see only algorithm needs to be a factor eventually, while case by (task) and annotator don't need to be.
but as far as I see, all other functions except significance ranking take care of algorithm being a factor implicitly.
so the solution you proposed earlier to define algorithm as a factor in Decision() is at least equally good if not better
algorithms <- factor(unique(object[[by]]))
I have added object[[algorithm]] <- as.factor(object[[algorithm]]) to challengeR.R as you suggested. Now everything works without any problem. No need of stating stringsAsFactors anymore during CSV read.
I created a feature branch here and made the change: https://phabricator.mitk.org/rCHALLENGER111379ce5ad6ff042d70479546eb61b4bdd5c268
Could someone else also try the solution? Then we can merge this to develop branch.
First, I tried the fix with R 3.6 and can confirm that it does not break the functionality there.
Would it be possible to test the expectation of the API in a unit test?
Yeap :)
I added tests in current future branch for checking class of “algorithm” column in challenge object.