The issue has been reported on GitHub:
https://github.com/wiesenfa/challengeR/issues/36
These are @wiesenfa's findings:
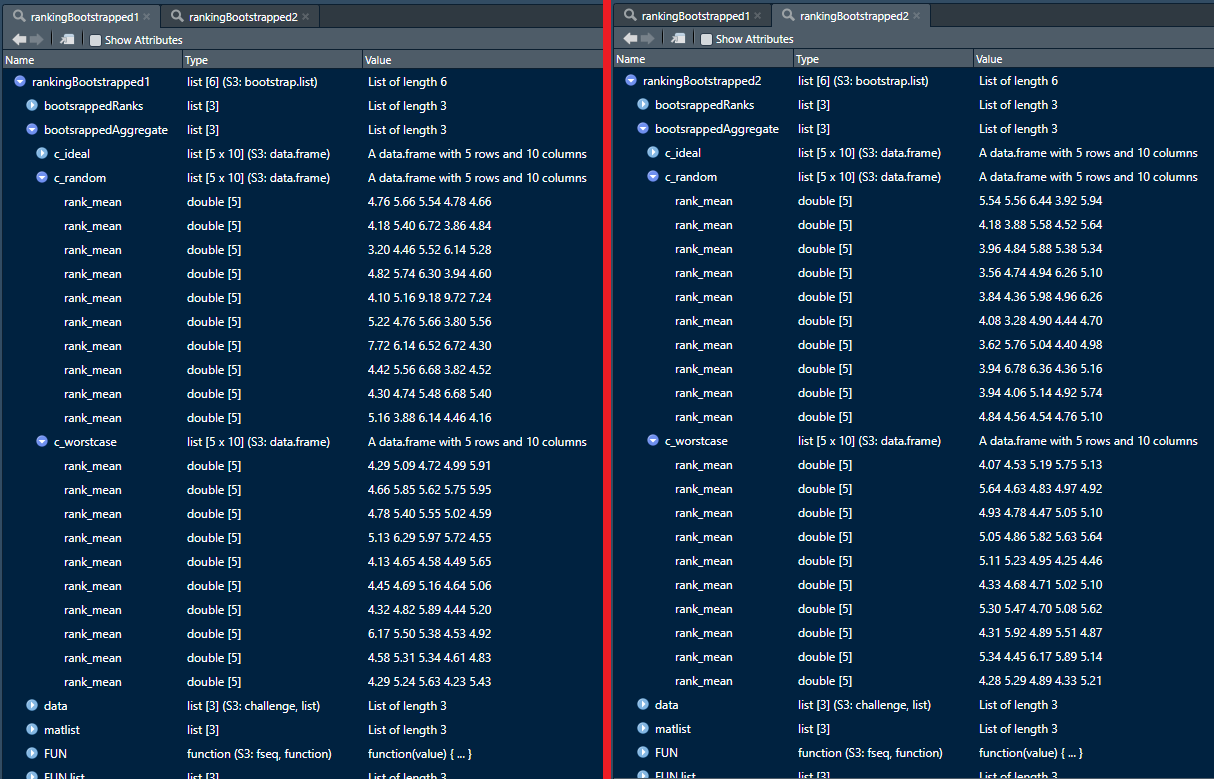
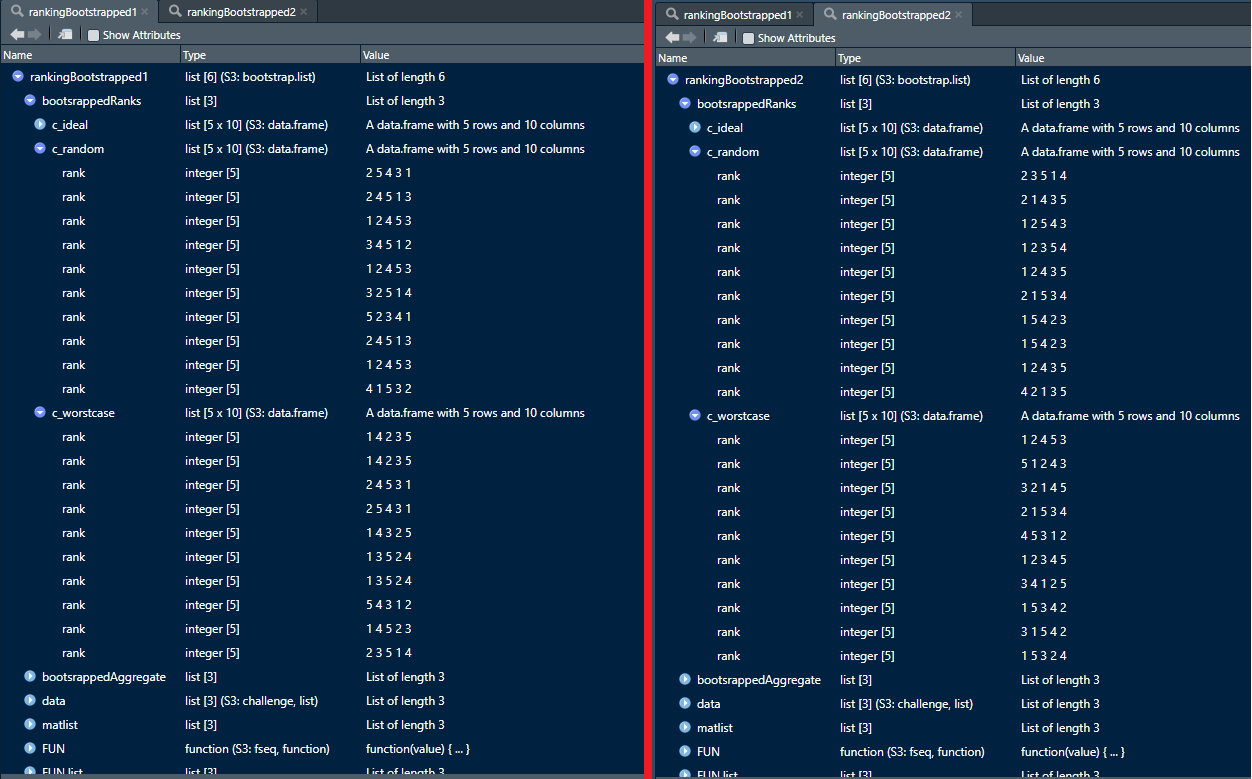
Parallelization currently leads to different results, but sequential computation not.
The solution is relatively simple though: Replacing in the readme (and vignettes probably)
set.seed(1)
by
> set.seed(1, kind = "L'Ecuyer-CMRG“)
changes the random seed generator and then it also works parallelized. I'd suggest to consider replacing the random seed generator also for sequential computation, either using kind = "L'Ecuyer-CMRG“ or kind = "default“, because otherwise the last generator used is applied until restart. As far as I understand both the default and L’Ecuyer have their pros and cons, but not sure which one is to be preferred for sequential computation.
See rough test routine attached:
It should be noted that parallelized computation will still not yield the same results as after sequential computation, thus to obtain the same results, the same number of cores need to be used. To achieve this, first a stream of random seeds would need to be generated which would have to be applied before each drawing of a bootstrap sample. This would require internal changes of the code.
I’d suggest to include a warning in bootstrap.ranked.list() if the default random generator is used in conjunction with parallelization:
if (RNGkind()[1]!="L'Ecuyer-CMRG" & parallel) warning("To ensure reproducibility please use kind = \"L'Ecuyer-CMRG\" in set.seed(), e.g. set.seed(1, kind = \"L'Ecuyer-CMRG\")“)